 088-26277376
088-26277376
 start@ambrero.nl
start@ambrero.nl




 072 56 26 500
072 56 26 500




De afgelopen vijf maanden heb ik bij Ambrero mijn afstudeeropdracht mogen uitvoeren. Het doel was ‘’Het ontwerpen en implementeren van een proof of concept voor een schaalbare architectuur voor een groot sensornetwerk’’. De opdracht besloeg de onderwerpen: Internet of Things (IoT) en Big data. Tijdens mijn afstudeeropdracht heb ik veel geleerd en met deze blog wil ik deze kennis en een aantal tips delen.
De opdracht; proof of concept
Mijn opdracht: het maken van een proof of concept, het ontwerpen van een schaalbare dataverwerking voor een sensornetwerk.
Het sensornetwerk bestaat uit luchtkwaliteit-sensoren voor consumenten die data versturen via LoRaWAN. Het geeft consumenten inzicht in de luchtkwaliteit van hun eigen omgeving. Daarnaast dragen ze bij aan analyses over een specifieke regio.
De bedoeling is dat deze dataverwerking op drukke momenten opschaalt om de datastroom aan te kunnen. En dat het op rustige momenten weer terug schaalt zodat het efficiënt gebruik maakt van resources. Er zijn twee belangrijke eisen gesteld:
- dataverwerking van minimaal 10.000 berichten per seconde
- dataopslag van minimaal een jaar
Is mijn data eigenlijk Big data?
Veel data betekent automatisch Big Data. Deze aanname wordt vaak gemaakt waardoor er onnodig tijd wordt besteed aan speciale databases en frameworks. Terwijl deze niet altijd beter, soms zelfs slechter, presteren dan conventionele oplossingen.
Ik bepaal of mijn data Big data is aan de hand van de drie V’s van Big data; velocity, variety en volume. In de afbeelding hieronder zijn deze te zien en het toont de relaties tussen de drie V’s. Alles in de binnenste ring is geen Big data. Wanneer er één of twee V’s buiten de binnenste ring vallen kun je overwegen om onderzoek te doen naar speciale databases en frameworks. Vallen alle drie V’s erbuiten dan heb je te maken met Big data!
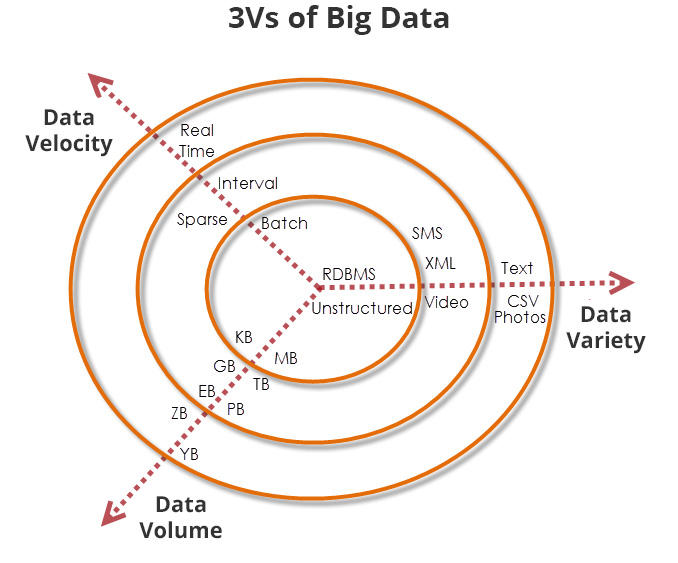
In mijn onderzoek is de velocity van de data; hoe vaak data wordt gebruikt tussen batch en interval. De variety is simpel, namelijk kleine berichtjes van 40kB. Het volume is echter erg groot, namelijk 10.000 berichten per seconde maal één jaar. Dat zijn ruim 300 miljard berichten met een grote van meer dat 13 terabyte. Er is dus een speciale oplossing nodig om efficiënt met de data om te gaan.
Het zoeken van de juiste componenten
Het is nog een hele zoektocht om de juiste analyse frameworks en databases te vinden voor deze applicatie. Het Big-Data landschap is namelijk enorm. Er zit altijd wel iets tussen wat goed werkt maar het vereist enig uitzoekwerk!
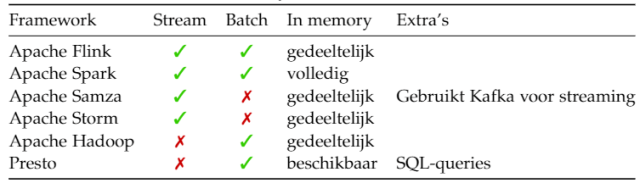
Uiteindelijk is mijn keuze gevallen op Apache Cassandra voor de database en Apache Flink voor het maken van analyses. Deze keuze heb ik op de volgende manier gemaakt:
1. Stel een lijst op van eisenIn het geval van het analyse framework zocht ik een framework met batch en stream analyse mogelijkheden.
2. Maak een lijst van frameworks en databasesHet is handig om voor iets te kiezen wat recent is en veel gebruikt wordt, de kans dat er genoeg informatie en ondersteuning beschikbaar is is dan groot. Maar ga ook niet gelijk voor de eerste de beste big-data database die bekend klinkt. Doe je onderzoek grondig.
3. Maak een vergelijkingKijk welke databases/frameworks voldoen aan je eisen
- Geen één gevonden? Zoek dan verder naar wat minder bekende oplossingen of kijk welke het dichtst in de buurt van je gestelde eisen komt.
- Zijn het er meerdere kijk dan welke het best binnen de applicatie past.
Vaak weet je pas echt of een framework goed binnen de applicatie past nadat je er een tijdje mee gewerkt hebt. Zorg er dus voor dat er genoeg ruimte is om te wisselen van framework.
Het creeëren van snelheid
Om de applicatie schaalbaar te maken is deze verdeeld in losse componenten. Ontstaat er bij een component een knelpunt dan wordt deze meerdere keren gestart om zo het knelpunt te verhelpen. Binnen de dataverwerking wordt RabbitMQ gebruikt als messagbroker tussen de verschillende componenten. Zo is er geen harde koppeling tussen en kunnen ze onafhankelijk van elkaar schalen. Daarnaast bevatten slimme frameworks zoals Apache Flink interne schaling waardoor ze erg snel zijn.
Optimaliseren door isoleren
Maar hoe achterhaal je de oorzaak van een traag component? In een ideaal scenario schaalt een component lineair, verdubbelt het aantal instanties dan zal de snelheid ook verdubbelen. In veel gevallen zal de hardware van het systeem waarop de applicatie draait ervoor zorgen dat een lineare schaling net niet haalbaar is. Wanneer het veel afwijkt, wijst dit op een limitatie buiten het component.
Het vinden van deze limitaties, binnen het component en/of erbuiten is een kwestie van isoleren. Ik blijf doorgaan met het isoleren van delen van het component met externe connecties totdat de schaling nagenoeg linear was. Hierdoor vond ik de bottleneck.
Uiteindelijk moest ik de volgende optimalisaties uitvoeren voor Apache Cassandra en de PostgreSQL database:
1. Batch-writes voor de databasesOm efficiënt gebruik te maken van de database connectie is het handig om berichten niet één voor één weg te schrijven maar ze op te sparen en periodiek weg te schrijven.
2. Concurency voor Apache CassandraBij speciale databases raad ik aan om eerst op te zoeken hoe zo’n database optimaal kan functioneren. In het geval van Apache Cassandra is concurency vereist om hoge snelheden te halen.
Het resultaat; 10.000 berichten per seconde
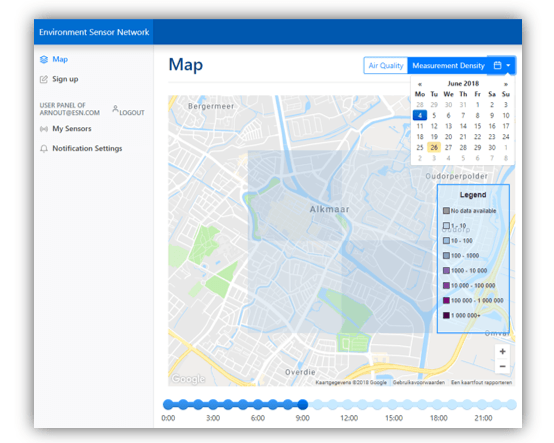
Inmiddels staat er een schaalbare applicatie die op een snelle en efficiënte manier data analyseert en verwerkt. Door het gebruik van slimme frameworks, efficiënte databases en schalende componenten kan deze dataverwerking nu 10.000 berichten per seconde verwerken. Daarnaast biedt het de gebruiker inzicht in de luchtkwaliteit en het aantal metingen per vierkante kilometer.
Een bijkomend positief resultaat… ik heb een 9 behaald met mijn afstudeeropdracht!
Tips
- Veel data betekent niet direct Big data!
- Kies bij voorkeur voor bekende Big data frameworks/databases voor de beste ondersteuning maar onderzoek de keuze hierin.
- Speciale frameworks/databases vereisen vaak een andere manier van werken, onderzoek dit.
- Verdeel je applicatie in componenten en zorg ervoor dat componenten onafhankelijk van elkaar kunnen schalen voor efficiënte schaling.
- Door te isoleren kom je erachter wat de bottlenecks van je applicatie zijn.
- Blijf optimaliseren totdat een component nagenoeg linear schaalt.
Arnout Schekkerman
Eindejaarsstudent Technische Informatica – Hogeschool van Amsterdam


